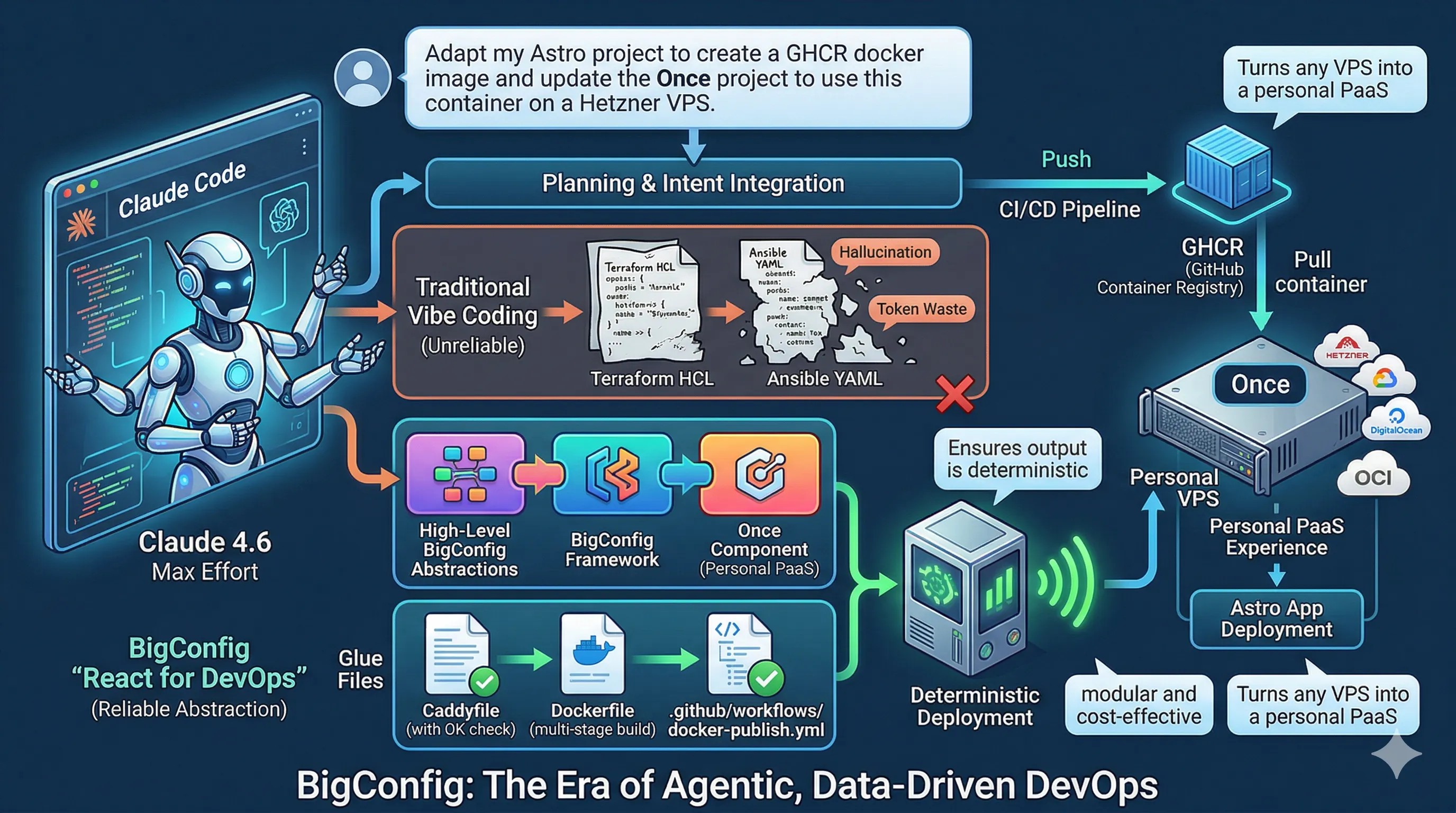
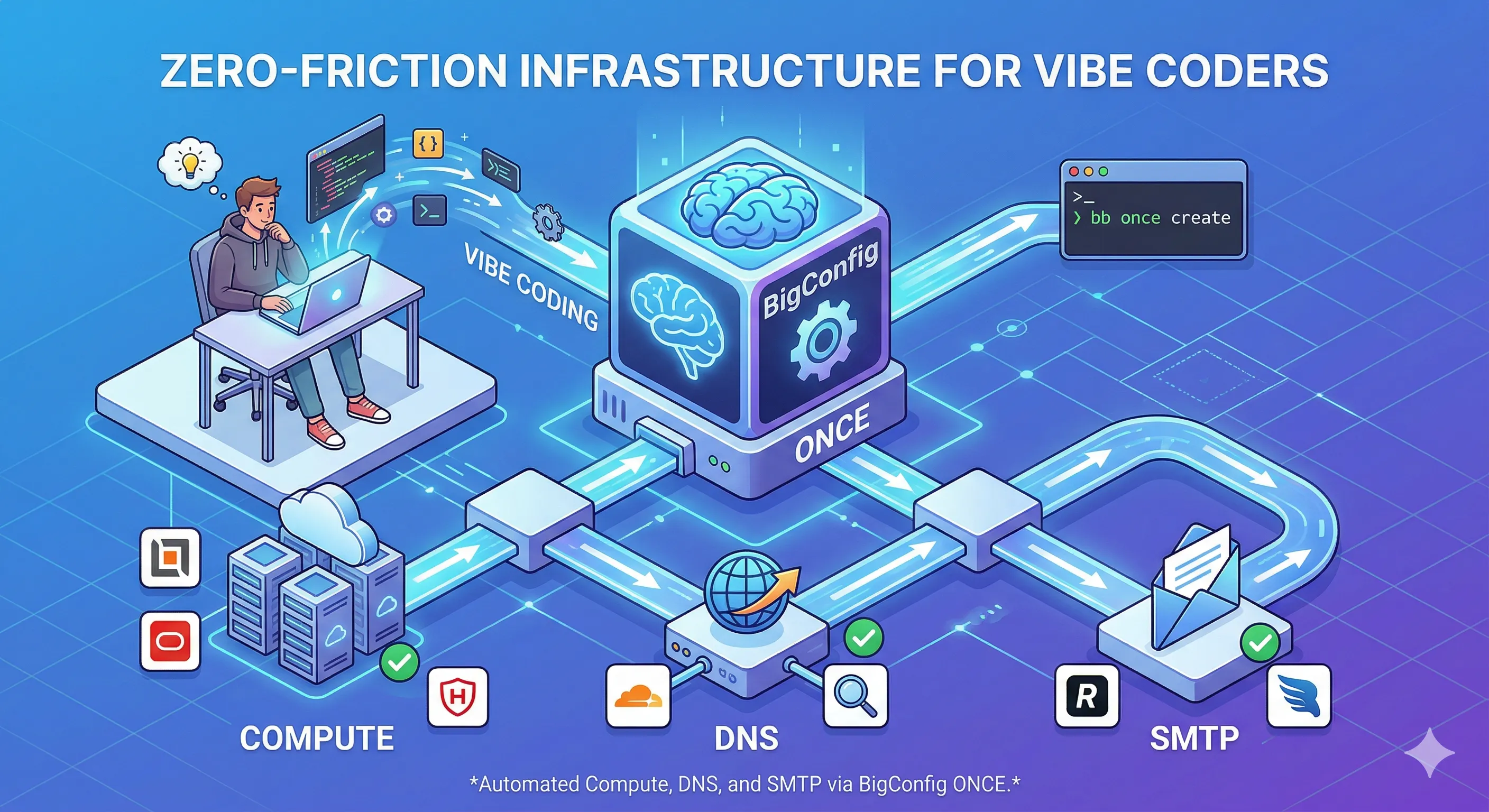
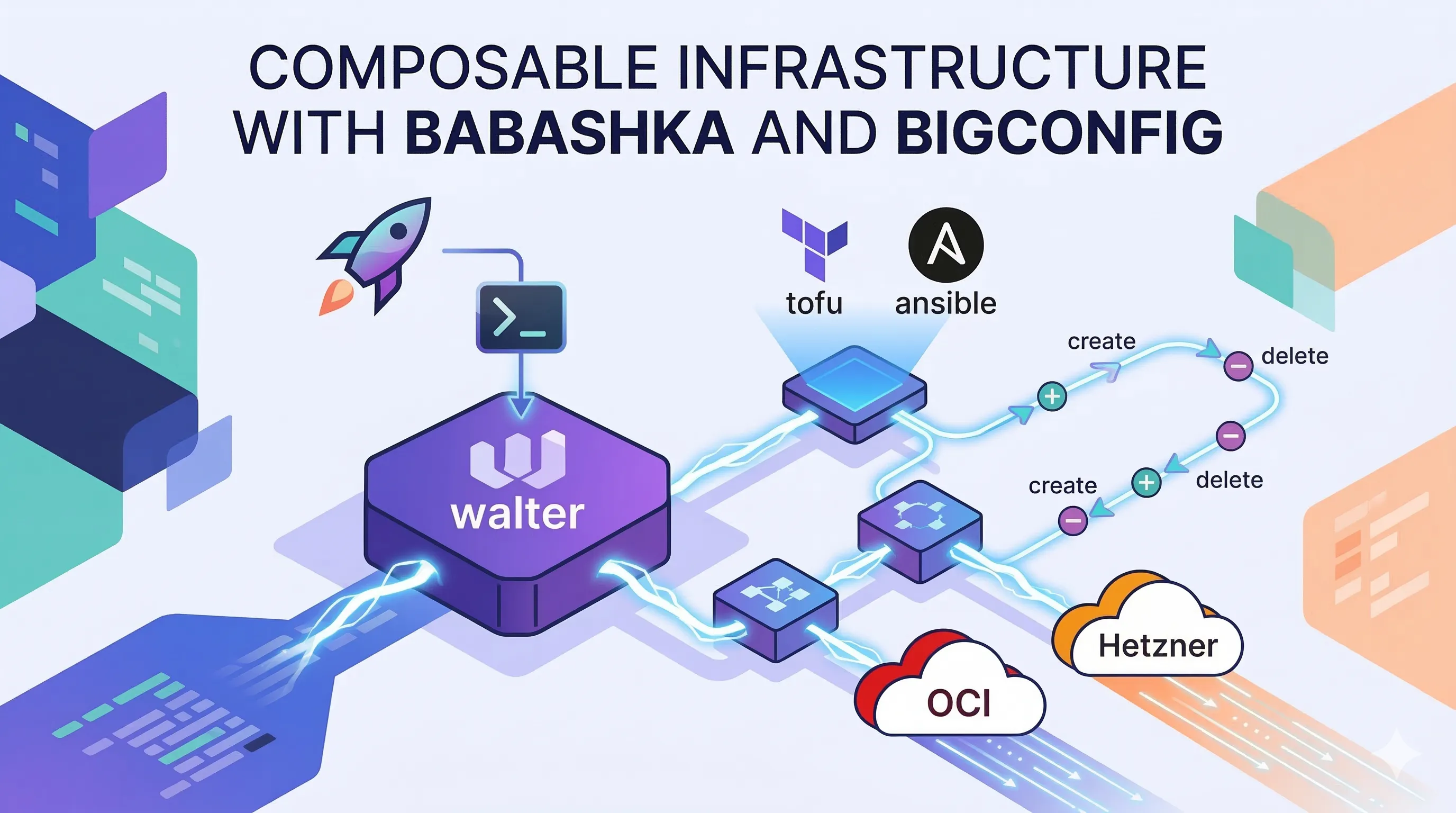
Can you build a professional-grade cloud platform without writing a single line of code? By leveraging BigConfig and AI, I created the blueprint of a full-stack infrastructure—complete with DNS, SMTP, and TLS—in just three minutes using nothing but Markdown and declarative data.
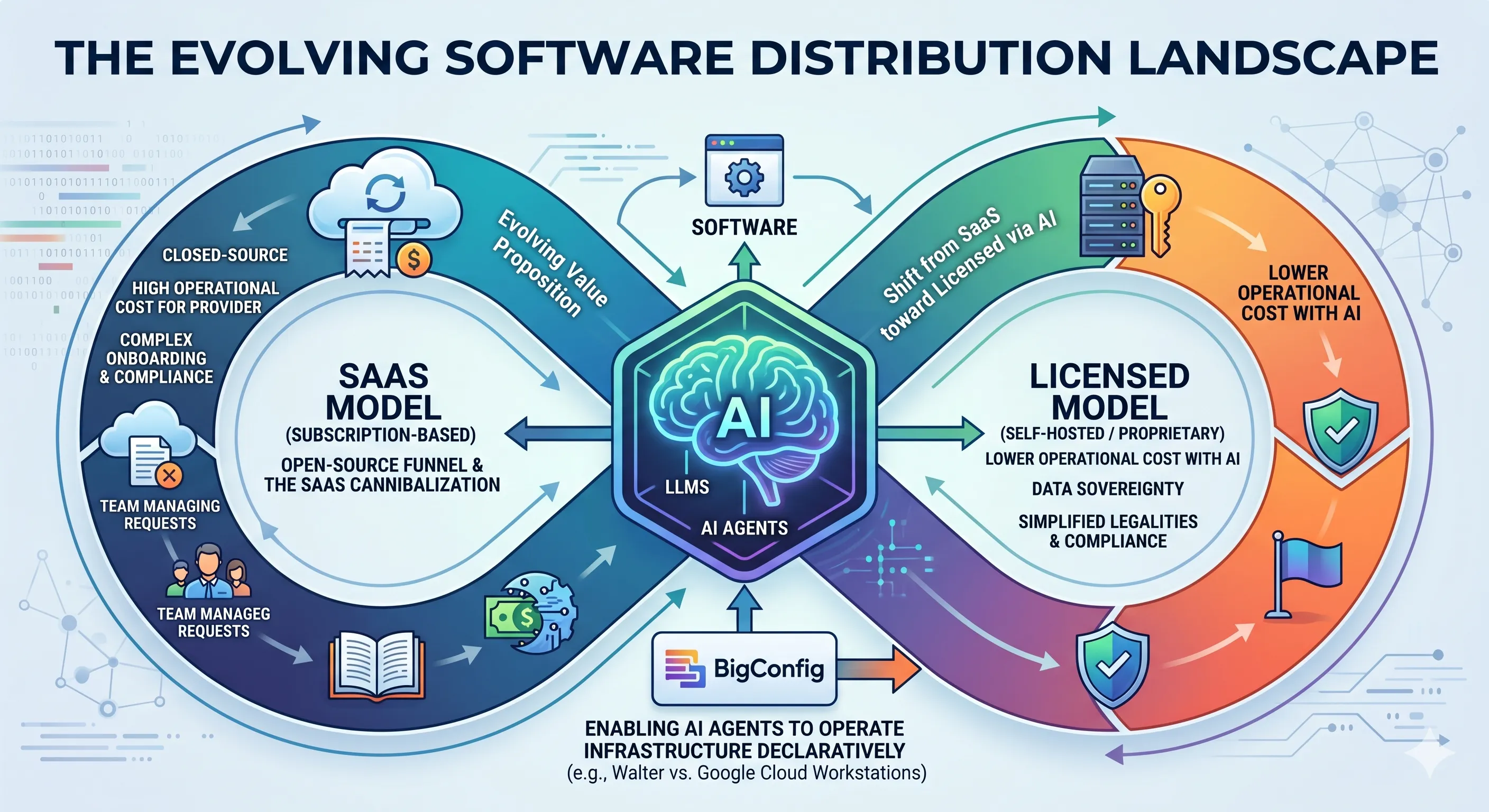
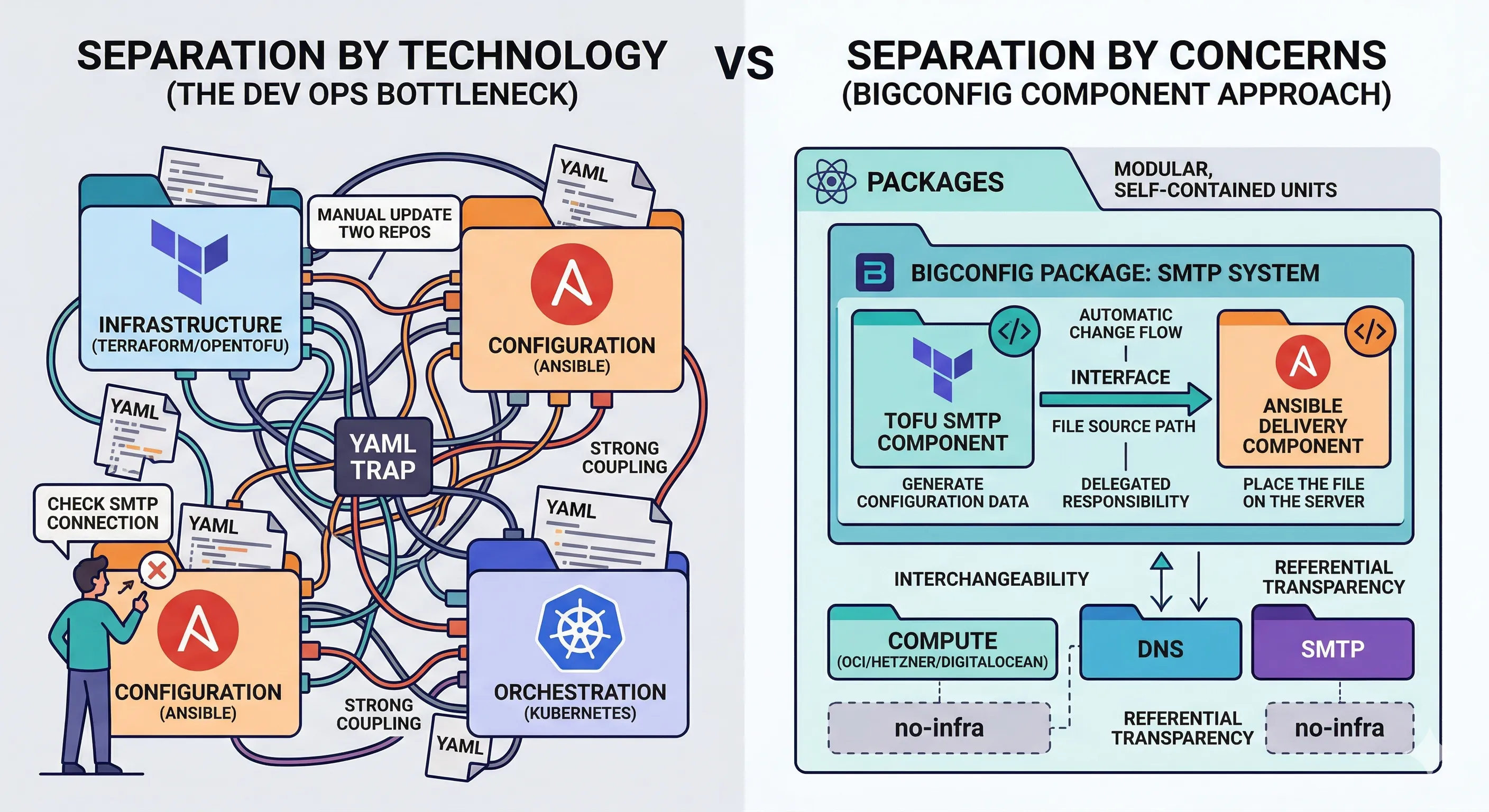
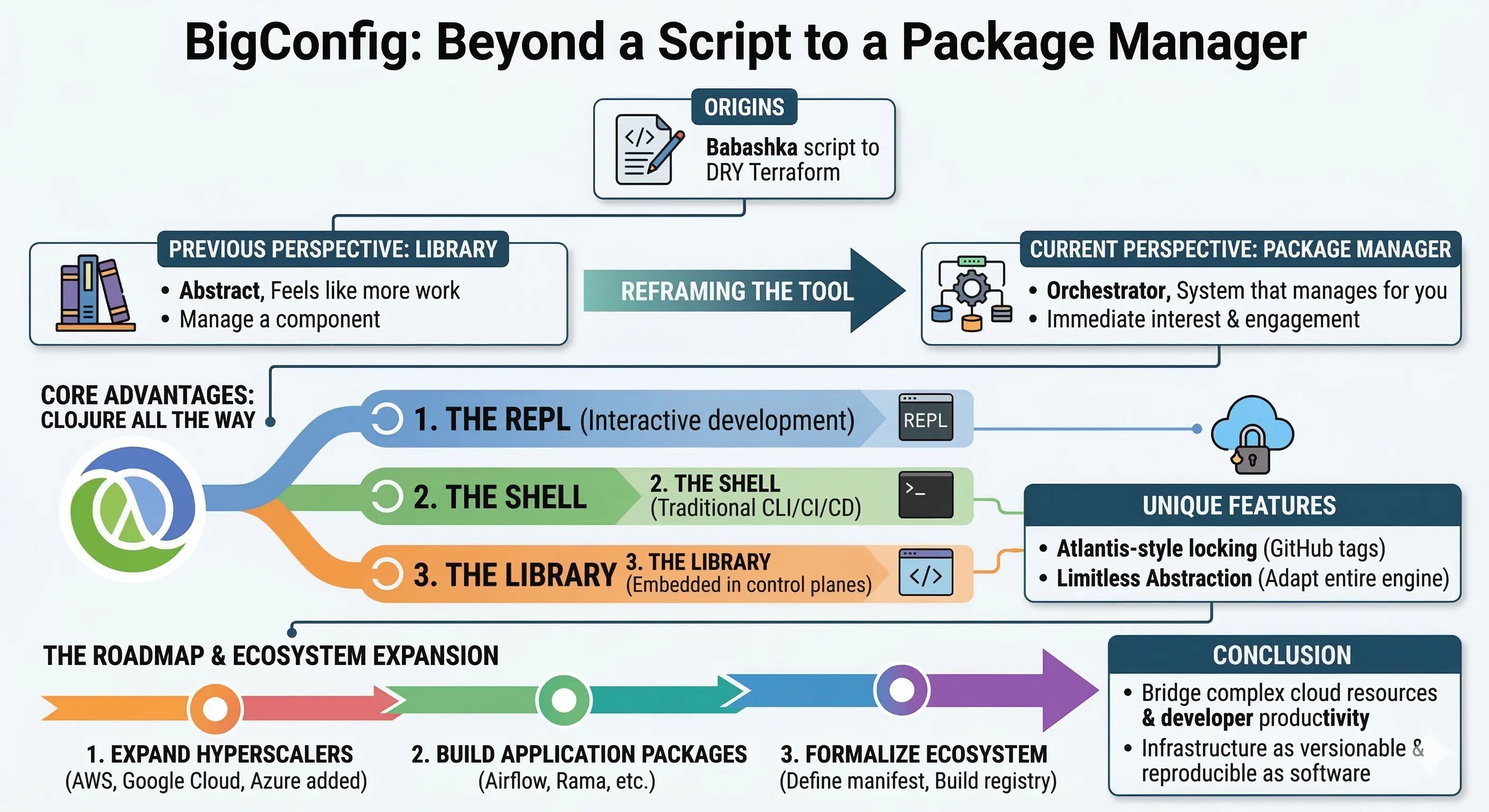
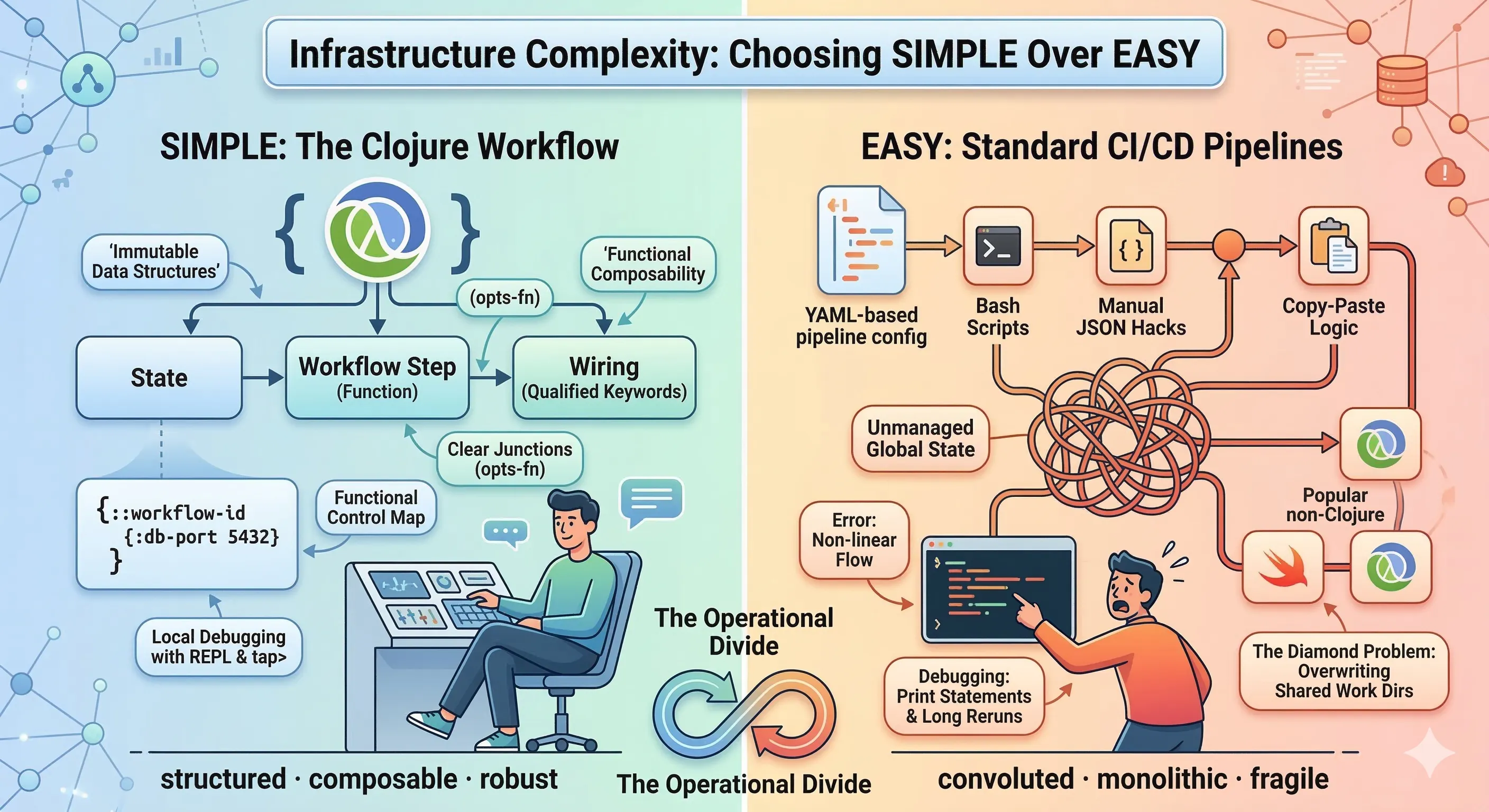
By treating infrastructure as “pure data” rather than complex scripts, BigConfig acts as the “React of DevOps,” encapsulating messy Terraform and Ansible logic into clean, reusable components. This post explores a hands-off workflow where a simple Markdown plan is transformed into a working blueprint, proving that with the right abstractions, non-technical users can manage non-trivial infrastructure as easily as filling in a configuration manifest.